







GPU One delivers production-ready environments across leading NVIDIA GPU platforms, supporting organizations that require the latest advancements in high-performance AI infrastructure:
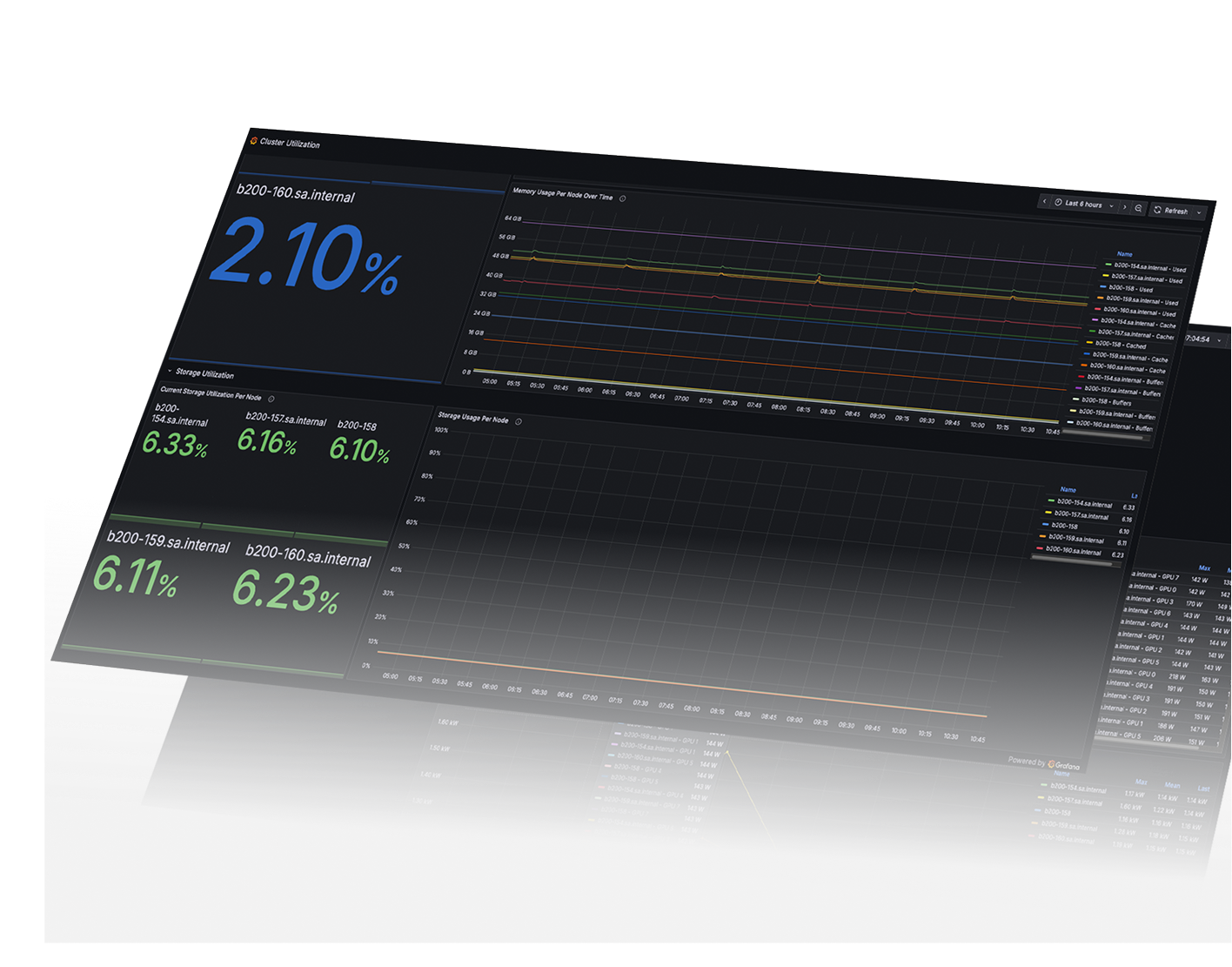
Each generation operates within the same validated platform architecture, networking fabric, security framework, and operational model.
Consistent performance. Predictable operations. Scalable capacity.
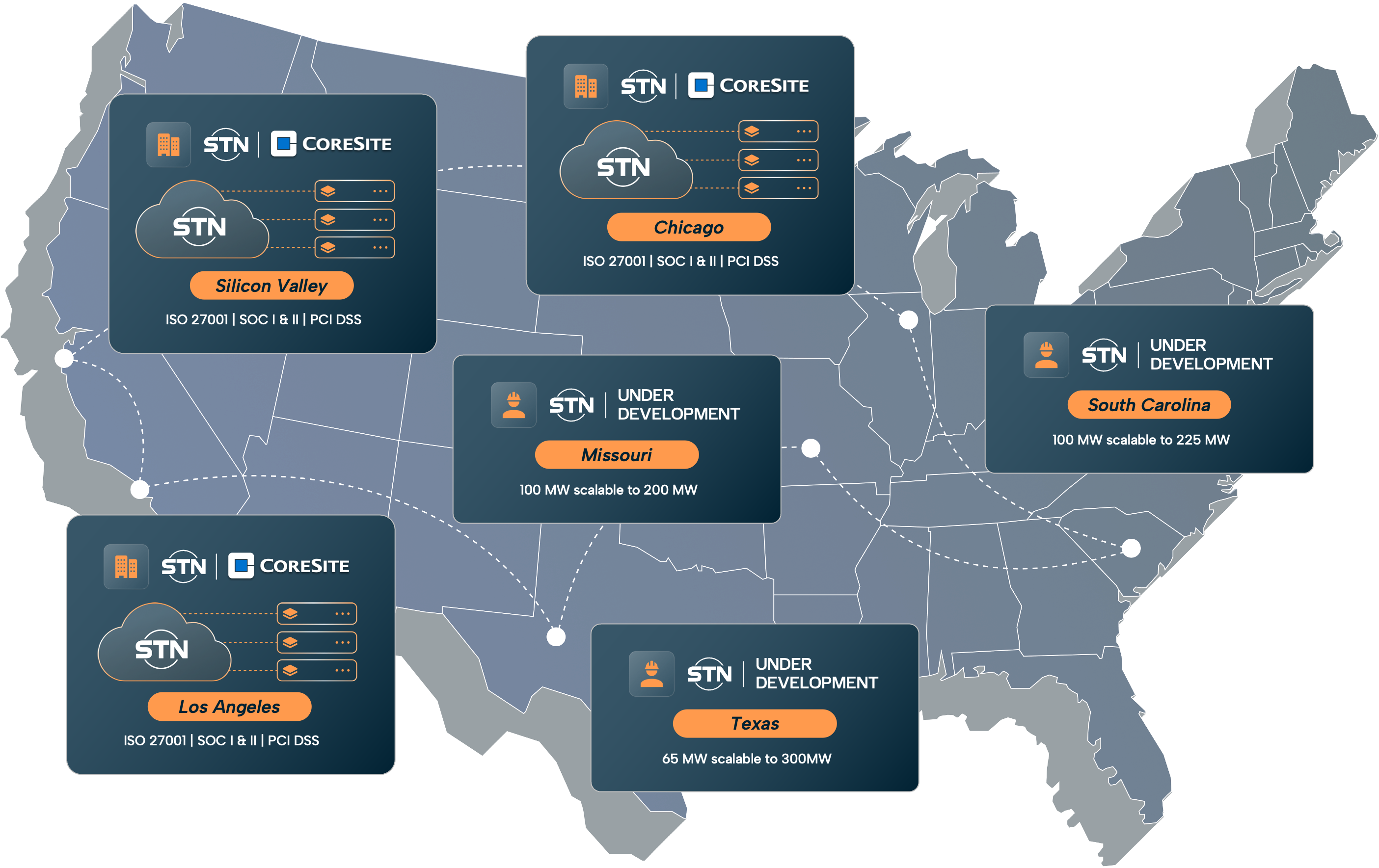
Active Locations
Under Development
Our services are designed for capacity growth, redundancy, and long-term infrastructure scaling.










Let’s build GPU infrastructure you can trust.
GPU One delivers production-ready AI infrastructure with the operational complexity removed.
From performance engineering to compliance controls, we run the platform so your teams can focus on models, products, and outcomes.
Curious about how it fits? Want to see what it’ll cost or need to chat through ideas first? We’re always here.

